May 12, 2025
Smarter ground models with construction site data

by VIKTOR

Loading...

Limitations of CPTs and current methods
Pile-driving into unknown soil causes waste and delays. In his master’s thesis investigation at the Port of Rotterdam, Amos Yusuf discovered that from his data set of 2,200 piles, 700 had to be discarded due to incorrect installation or bad data. Nearly one-third of the total!
Although above-ground IoT sensors and drones can already feed Building Information Models (BIM), which are a digital representation of a structure’s physical and functional characteristics. Below ground, engineers still rely on sparse CPT (cone penetration test) points. Updating a digital twin without little CPT data results in designers having to build with large safety buffers, driving up material use, CO₂, and cost. Better ground-model updates can potentially promise higher design confidence and leaner installation schedules.
Soil and Data Challenges
Before any modeling could begin, the data had to be cleaned. Amos spent weeks going through the records, and in the end, only 1,500 of the original 2,200 piles were usable. That’s a relatively small dataset for machine learning and made the task more complex.
Because of the limited and uneven data, advanced deep learning models weren’t a good fit. Instead, Amos chose a Random Forest algorithm—a simpler, proven method that works well with smaller datasets and still delivers accurate results. In projects like this, the type and quality of data often shape the technical approach from the start rather than the amount of data.
The model was trained using key variables that are routinely recorded during pile installation but rarely analyzed afterwards. These metrics, once cleaned and organized, became the foundation for a model that could predict changes in soil layers without needing to gather more CPT data from the field.
Soil Insights from Pile Data
Amos’ research started with the goal of optimizing piling speed. However, four months of research shifted the initial goal into the updating of soil-layer models from pile installation in near real-time.
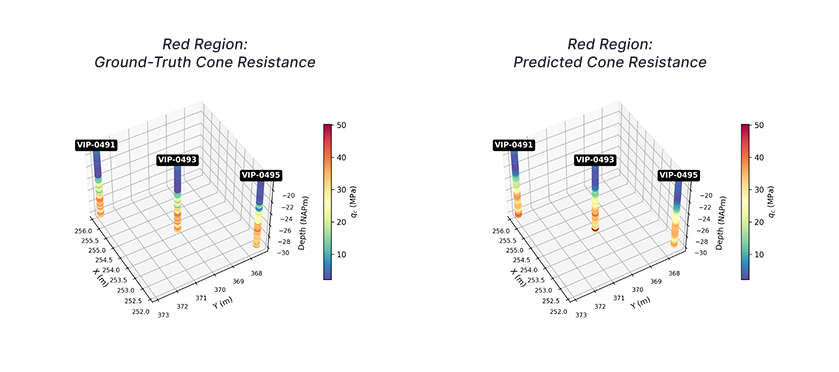
By training a Random Forest classifier on pile-driving logs, Amos was able to achieve 85% accuracy in predicting subsurface composition. No additional CPTs required!

Trusting the Process
Amos’s biggest lesson? “Your first idea isn’t always your best one; you have to keep developing it,” he reflected. “The process—how you explore, pivot, and persist—is more valuable than any initial plan”.
Machine Learning in AEC is not plug-and-play: it demands iterative trial-and-error, rigorous data prep, and interdisciplinary skills that can only be learned through curiosity. As Amos put it, “I didn’t just broaden my own skills—I added entirely new ones. And I think there aren’t many geotechnical engineers who also understand machine learning models from robotics, or vice versa.” Hands-on ML research cultivates skills that elevate both your work and the entire industry—too few professionals currently bridge AEC and data science.
Next Steps
Getting started with Machine Learning in Geotechnical engineering doesn’t mean overhauling everything at once. It starts with better use of the data you already have (like pile-driving logs) and a willingness to experiment. What really makes a difference is combining engineering know-how with data science skills. When those two worlds come together, even small pilot projects can lead to big wins: more accurate ground models, fewer surprises during installation, and less waste overall.
If you're curious about what this looks like in practice, check out our customer case on to see how it all came together on another project.
Want to know more about the possibilities with VIKTOR.AI and how it might help you leverage your data? Feel free to book a demo!
Start building apps for free