September 07, 2021
AI and Machine Learning in Engineering and Construction

by VIKTOR


Download the white paper and get INSPIRED
Learn how collaborative parametric design models allow you to work together for better solutions.
In this blog, we answer the following questions:
- What is Artificial Intelligence (AI)?
- What is the difference between AI and machine Learning (ML)?
- How can AI be used in organizations?
- What does it take to build a machine learning application?
- What are some examples of machine learning applications?
- What is VIKTOR?
Note: You can use the navigation bar bellow to get directly to the topic of your choice!
AI explained
Definition of Aritifical Intelligence
As the world keeps on innovating, Artificial Intelligence (AI) gets heard and talked about more and more often. Even though AI has become a fairly mainstream topic these days, a lot of people still struggle to provide a clear definition of it. This is not strange, because there are many distinctive types of AI that all have their own specifics. For example, regarding their level of sophistication. If we divide them based on that, we end up the with these four groups:
-
Reactive AI: This is the most basic type of AI. It provides a predictable output based on the input it receives and always reacts to identical situations in the same way. Examples of Reactive AI are email spam filters and the Netflix recommendation section.
-
Limited Memory AI: Limited Memory AI learns from the data it has been fed, It consists of machine learning models that store the data and use it to ‘learn’ and make more accurate predictions and recommendations in the future. An example of this are self-driving cars. These use data that was collected in the recent past to make decisions. For example, they use sensors to identify people that cross the street or spot traffic signals and other factors that need to be considered and anticipated whilst driving.
-
Theory of Mind AI: This type of AI goes a little further than the previous ones. It refers to the ability of machines to make actual decisions that can be compared to decisions made by humans. Such machines can for example detect, understand, and remember emotions and can adjust their way of interacting with others based on that. For example, if you say you are hungry, the AI may offer you an apple to fix it!
-
Self-Aware AI: This type of AI is the most evolved one and is also the only one we have yet to develop, It refers to the ability of machines to become self-aware and have an actual consciousness. Whether this will ever happen, is a question that is yet to be answered.

The most basic types of AI (Reactive and Limited Memory) are also the most commonly occurring ones. From these two, Limited Memory AI is currently the most popular and widely used type of AI. Read more about the four types of AI.
Impact of Artificial Intelligence
As of today, the Engineering and Construction industry is still one of the least digitized industries. That is why there is still so much room for improvement and implementation of new developments to facilitate all kinds of processes. From product manufacturing, to services, design generation, and workflow automation and optimization, AI can be used to optimize all kinds of processes in all kinds of industries. The decision to start implementing AI can be a difficult one because it leads to both a lot of opportunities as well as challenges. It is our own choice to decide whether we are going to use it to our advantage or not.
AI versus ML
When people decide to start implementing AI into their organization, most choose to use machine learning. ML is not only an abundant but also a cheap technique to create more value for your company. For example, ML can help you improve customer loyalty and retention and hire the right people for the right position. That is why, in this blog, we mostly focus on the implementation of ML to improve organizational processes.
Differences between AI and ML
The differences between machine learning and artificial intelligence may be hard to explain sometimes. First off, because AI is hard to define on its own. Second, because ML is actually a type of AI.
AI, simply said, refers to the capability of a machine to perform a certain ‘smart behaviour’. ML is not a machine but an algorithm that learns patterns from datasets to predict future outcomes, recognize patterns, or suggest different classes to the data. Something that humans simply would not be able to do. This means that with ML, you can for example teach a system to perform a specific task without providing it the specific instructions by feeding it with ‘training data’ that enables it to learn and detect patterns.
Types of Machine Learning
Even though all ML algorithms rely on data to learn their skills, there are also a lot of differences between how the algorithms use this data to learn. Just as AI has four distinctive types, there are three commonly occurring types of ML:

- Supervised Learning: This is a type of ML in which both the input and output of a (training) dataset are already known to the machine. This means that when an algorithm is fed a certain input, it is also fed with the corresponding output. Besides this, the algorithm also generates its own output. In case of errors between the algorithm’s generated output and the predefined dataset output, the algorithm adapts itself to produce the desired output. It therefore ‘learns’ from the dataset which input values should reproduce what output values. For future input data, the algorithm can now predict an output. This type of ML is often used for classification problems, such as regression problems, such as logistic regressions or decision trees, and regression problems, such as linear regressions and regression trees.
- Unsupervised Learning: As you may expect, with Unsupervised Learning the algorithm gets no help from the user. This means it has no way of comparing its own output to an already predefined and correctly labelled output. Instead, it gets fed a certain input and detects patterns by itself, with the goal to identify some structure in the data. This type of ML is often used to segments groups (data, people, maps) based on similar attributes (for example the Netflix recommendations). We call this clustering.
- Reinforcement Learning: With this type of ML, the algorithm discovers by itself which actions yield the greatest rewards through trial and error. The algorithm wants to make the right decisions, as its objective is to take the actions that lead to the biggest reward in the quickest way possible. In other words: Learning the most efficient policy, such as with Pacman in this YouTube video.
Supervised versus Unsupervised
The two most commonly used ML techniques are Supervised and Unsupervised Learning, as these are the fastest and cheapest to implement. The main difference between the two comes down to the labelled/unlabelled data that is fed to the algorithm by the model. When you have to choose between the two types, it important to carefully evaluate your input data (labelled or unlabelled?), define your goals (recurring problem to solve or new problem to predict?), and review your algorithm options (can it support your data volume and structure?). Answering all these questions will let you know whether you are looking to do a classification, regression, or clustering and with that you also know if you need Supervised or Unsupervised Learning.
Note: When you apply Unsupervised Learning, the results will be less transparent, because you cannot see how the model got there. The output may therefore be inaccurate. Unsupervised Learning simply puts persons, datapoints, and events into categories without providing information on how those categorisations came to be. A movie recommendation system can for example recommend Harry Potter because you like Star Wars because of a random reason like 'all people with your birthday also they like these movies'. In reality, it is very unrealistic to assume that a birthday influences what movies a person likes. An unsupervised learning algorithm does not know that and might retrieve non-causal correlations like this from a dataset.

Where Unsupervised Learning is often used for clustering of data, Supervised Learning is used for classification and regression analyses. People often want to use ML to cluster data for things such as customer segmentation, targeted marketing, and recommender systems. Using ML to classify data is often done for things as image classification, identity fraud detection, diagnostics, and customer retention. Regression analyses on data are for example performed to detect population growth and advertising popularity, estimate life expectancy, and forecast markets and weather.

Because classification of data is a popular way to use ML, this is also used to for example recognize digits based on pixels. This works by linking the composition of certain pixels to a specific category and is roughly the same principle as a camera with facial recognition. What happens when the camera ‘sees’ your face, is it actually recognizes the pixels that depict your face on film. These pixels are classified as ‘a person’s head’ and are therefore recognized as one. With digit recognition, the same goes for the pixels that make up the number, except for each number the pixels are classified into a category anywhere from 0 to 9 instead of ‘a person’s head’ or ‘not a person’s head’.

AI and ML in organizations
ML is a popular type of AI for many businesses to create the most value from their work and efforts because it is both a 1) abundant and 2) cheap technique.
- Abundant, because there is an ever-growing amount of (varieties of) data. It is important for companies to find a way to quickly and automatically run analyses and generate accurate results, as this has simply become impossible to manage for humans. In this, ML can be used to analyse, categorise, and store lots of data.
- And cheap, because computational processing has become a lot cheaper and more powerful, and data storage is more affordable than ever. Because of that, a lot of companies started using ML to build precise models to identify profitable opportunities, enhance decision-making and security, provide accurate results, lower change of errors, and avoid risks, and even more.
“You can have data without information, but you cannot have information without data.” – Daniel Keys Moran.

Deep Learning
But wait, these are not the only reasons for why companies have increasingly started using ML. Over the past few years, technologies that facilitate the application of ML have become considerably more accessible. This has led engineers with a limited amount of training to be able to apply ML to their work. A versatile ML technique that is now often used by engineers is the Deep Learning algorithm, which is a type of Supervised Learning that uses so-called Artificial Neural Networks (ANN) to learn from datasets.

Artificial Neural Networks
ANN’s were initially inspired by the brain, as they narrowly resemble the brain’s structure that consists of neurons that are wired together. A fully connected ANN consists of subsequent layers with each their own number of units that process the input per layer. Because input is processed per layer, the input that is processed by a certain unit in a certain layer each time depends on the output from the units from the previous layer. Therefore, ultimately the final output depends on the processing that is done by all the units in the last layer of the network.
As ANN’s are a type of Supervised Learning, these networks also need to go through a learning phase before they can actually be used to recognize patterns and produce the desired output. Because the ANN is trained in the same way as with Supervised Learning, it can be used to automatically learn complex patterns in datasets. Due to that ability, they have become the foundation for the development of many life-changing applications in all kinds of industries, from AI platforms built on ANNs that process input (text) to translate web pages themselves (thing Google Translate!), to ANNs that are able to detect spam mail, and to Deep Learning algorithms that use ANNs to predict the likelihood of certain future events.

To give another example of what can be done with ANN’s, we will refer back to our first ML example with the number classification. For this, a certain type of ANN is often used for processing that performs particularly well in image recognition, called the more complex Convolutional Neural Network (CNN) algorithm.
AI and ML in today’s industry
Even though ML may sound very high-tech, all these automated technologies have been around for quite a while already (think about online advertising, cloud documents, automatic updating, etc.). It can still be difficult to understand how we have gotten here in the first place. Some people may think that the automation of certain tasks is here to replace human labour, while instead the purpose is to make people’s lives easier!
That is why companies in all kinds of industries (not just tech!) have started using the benefits of AI, ML, and its many applications to increase productivity and expand possibilities. A few examples of well-known companies that use these techniques are:
-
Google, of course for a lot of things. Google build a prototype software that has the ability to mimic the human mind and even has short-term memory. Additionally, Google owns ‘Nest’, which is voice assistant that can be used to control a series of home products (‘Smart Home’) that leverage AI technology.
-
IBM build an AI machine called Watson that can detect patterns, ask questions in human voice, and answer (correctly) as well. Watson has the ability to search through loads of information within seconds. This allowed him to win the popular US TV show Jeopardy and conducted research that may help eradicate cancer.
-
BMW uses AI to analyse component images from their production line and scan for deviations to detect possible errors in their manufacturing.
-
Boeing uses Augmented Reality to scan images of their airplanes that are sent to a processing platform to detect abnormalities in the design.
-
Facebook, Microsoft, Yelp, Pinterest, Twitter, HubSpot, and many more…

AI and ML in your organization
A lot of companies are already reaping the benefits of AI, sometimes even without people really noticing that AI is at the cause.
As ML allows organizations to turn (large) datasets into knowledge and enable them to act on it, it is clear that it could do no harm to incorporate ML applications into your organization as well. However, this is of course easier said than done. Before you successfully do this, there are a few organizational aspects that have to be considered first.
Organizational challenges
Of course, the idea of applying new technologies, such as ML techniques, to boost the performance of your organization sounds great. But don’t forget that simply applying some new digital tool is not an immediate and overnight solution to your problems. Right now, many of these developments don’t get much further than the prove of concept. How come? The answer lies with the fact that the people that are in charge often only think about implementing the solution and forget about two other important factors, which are the processes that will be automated and the people that are going to work with it.
Therefore, for your digital solution to work, there are three important factors that need to be paid enough attention to in this order:
- First people: Before you can use your digital solution, the people that are going to use it should be willing to adapt to this change. They may not (yet) be convinced that it will work out well or that they are able to operate it. Additionally, your digital solution may affect the way that they do their jobs. It is very well possible that they are not afraid that this will not be in a positive way or that they are simply not ready for this change. Thus, getting your people on board should be the first step to applying new digital solutions, like ML.
- After you have convinced your people, the process follows: Changing entire processes is not as simple as it seems. That is why you should consider very carefully which process are possible and also profitable to digitize before you start applying a digital solution that may ultimately not work. Ask yourself questions. For example, “Is it possible to automate this process using ML?”
- Last but not least, you implement the technology: Only after you have looked at the people and process components, you can start thinking about actually implementing a digital solution that suits both your people and processes. The focus of your digital transformation should be 80% people and 20% technology.
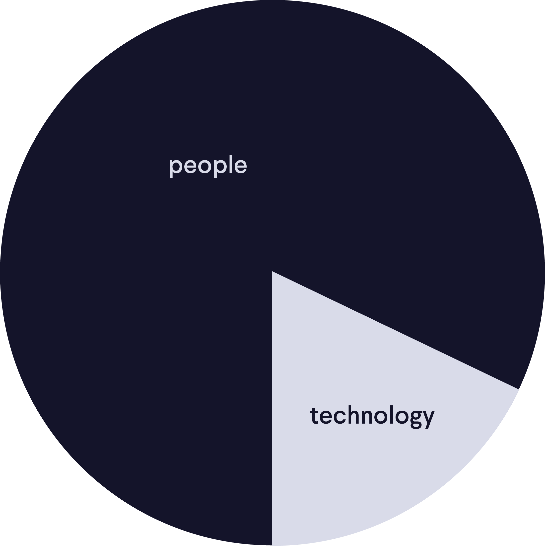
There is a lot that goes into implementing new technologies and doing so is certainly not done within one day. It is important to strategically take on this process of digitally transforming your organization. Read more on how to do this in our white paper “People first, tech second: The way to boost digital transformation in the Engineering and Construction industry.”
Thus, it is important to look carefully at the people and processes in your organization that are connected to your digital solution before actually implementing it. Once you have done that, the next step is to narrow down the requirements for this solution.
How to build a ML app
Now that we have discussed the organizational aspects of applying new digital solutions such as ML techniques to your business, you are going to take a deeper look at the mechanisms behind building such an application.
These steps you need to take to build your application are as follows:
- Define your problem
- Gather your data
- Choose your measure of success
- Set your evaluation protocol
- Prepare your data
- Develop your model
- Draw your conclusion
Step 1: Define your problem
The first step to building a ML application actually has to do with the process part of digitally transforming your organization (so: After people, before technology).
Here, you have to define the problem: What process do you want to replace using ML?
Note: Because ML is able to recognize patterns in datasets and the algorithm has to be trained to recognize them with training data first, you can only use ML if:
- The outputs can be predicted given the inputs
- Your available data is sufficient enough for the algorithm to learn the relationship between the inputs and the outputs
Step 2: Gather your data
If you want your prediction to be more accurate, you have to collect large amounts of input data with good quality to train your algorithm. More and accurate data equals more accurate predictions. We are telling you this because the importance of the preparation of data is often underestimated. The algorithm can only be as good as the quality of the data. Data preprocessing: filtering out faulty data, data normalization, cherry-picking important features, etc., is what makes or breaks a successful ML application.
“The machine learning result can only be as good as the data it receives” – Lars Janssen, MSc Student Applied Physics at Delft University of Technology and R&D Intern at VIKTOR
Step 3: Choose your measure of success
This factor is really important because in order to prove your success, you have to make it measurable somehow. Therefore, you should define the goal you want to reach using ML somehow and determine how you are going to measure this. This goal should both be in line with both your business’ broader objective and the type of problem that you want to solve (using ML0, such as 'I want to deliver good service to our customers. This can be done by using ML algorithms to predict and optimize the time it takes us to deliver a project'.
Step 4: Set your evaluation protocol
In the third step you have decided on what your goal is. Now, you also have to decide on how you are going to measure it. This often depends on the type of class of the problem you want to solve (clustering, classification, regression).
Whenever you measure performance, you will mostly end up with a score to indicate how well your model has predicted the outcome. For example, for classification you get a score for classification accuracy (in %), which is the total correct correction of the ML model divided by the total predictions made by the model x 100.
So, what you have to do is pick a dataset that you will use to train the model with. You do not use all data for training but hold a smaller part of it aside, this smaller subset is called the validation dataset. After each training step, you provide the model with the validation dataset, and use this to test the accuracy of the model's performance on this validation dataset. As the number of training steps increase, the model’s performance with respect to the training set improves. It is however crucial to monitor whether the model’s performance with respect to the validation set improves as well. If this is not the case, it shows that the model is ‘overfitted’ on the training set. With overfitted we mean that the trained model is improving its performance at predicting ‘unseen’ datapoints. The goal of machine learning is to apply the model for the prediction of future (unseen) datapoints. The observation of a model performance improvement on the validation dataset is therefore crucial.

Step 5: Prepare your data
Now that you know what your problem is, what data you are going to use to solve it, how you are going to measure whether you solved it successfully or not, and how you are going to do perform these measurements, you still need to prepare your data before it can be ‘fed’ to the ML model. For this you have to:
- Check for missing data. If there is any data missing, these fields can either be deleted or you can insert the missing values yourself manually.
- Make sure the algorithm can interpret the values correctly. Is your data categorical? Then the features of this data can either be nominal (e.g. type of pile) or ordinal (e.g. size of pile). For the ML model to correctly interpret these values, you have to assign numeral values to these features (e.g. pile type 1 = 1, pile type 2 = 2).
- Scale the features. In cases where you have multiple features on different scales, you have to rescale them so that the scales align and they can be compared to each other. This can either be done by normalization (scaling on a range from 0 to 1) or standardization (centering at 0 with a range of 1).
- Select the features that are meaningful. For your ML model to be the most accurate, you must make sure that there is as little redundant data as possible. Otherwise, the model will get too complex compared to the training data and will not be able to predict accurately.
- Split your data into subsets. To get the best predictions, you have to split your data into three subsets: The training set, the validation set and the test set. With the training set, the model is trained. The validation set is used during training to evaluate whether you are not overfitting the model too specifically to the training set. The test set is not used during the training process, the model has therefore never seen this dataset. The evaluation of this test set therefore gives a realistic approximation for the model’s performance for future predictions.

Step 6: Develop your model
Before you can develop your actual model, you first have to come up with the baseline: A benchmark model to measure the performance and accuracy of your ML algorithm. This benchmark model is used to determine what your actual model has to look like to come up with the best score. So, for example, depending on the number of groups you have to split your data in or what the best scoring method is for your data (classification, regression).
Step 7: Draw your conclusions
After you have chosen the most accurate model and used it to predict data, you are going to interpret this data and draw conclusions from it. What do the predictions say about the future?
Examples of ML apps
The Pile Foundation application
Voorbij Funderingstechniek is specialized in executing all kinds of foundation work. With that, they are leaders when it comes to delivering carrying capacity for infrastructure, hydraulic engineering, utility construction, and industrial construction. They offer their partners creative and innovative solutions to their problems and together carry the success of realizing beautiful projects. Voorbij used the VIKTOR platform as application development platform to build several modules that support them in optimizing various of the processes that occur during these projects, for example for the (re)design of pile foundations and, in this case, the estimation of pile driving time.
Foundations of buildings in the Netherlands often require a deep foundation that makes it possible to transfer building loads to a subsurface layer further down, because a solid layer that can facilitate large foundation loads can often lie deep beneath the surface. Therefore, the foundations of large constructions (e.g. distribution centers or traffic overpasses) can require thousands of piles to be driven into these depths for stabilization. For both cost estimation and scheduling it is important to know the correct amount of time it will take to drive these piles.
Currently, pile drive time is estimated by exploiting knowledge about the soil through CPTs (Cone Penetration Tests) that are taken from the location and used to classify soil composition (e.g. sand or clay). Because recently the registration of pile drive data has significantly increased, it has become possible to improve the predictions of pile drive time in future projects by applying Machine Learning techniques, also using customer pile drive measurements and CPT data. As a ML algorithm, an Artificial Neural Network is used to predict penetration speed values based on CPT data by training it on measured pile drive measurements and the corresponding CPT data.
The ML model is implemented within an application development platform so that engineers are enabled to train and apply the ML model to the engineering process themselves.
Learn more about Voorbij’s projects on the VIKTOR platform.
Next, it is described stepwise how Voorbij build their ML application.
First, Voorbij defined the problem. They wanted to predict pile drive time. For this, there was sufficient input data (recently significantly increased even), since pile driving speeds and soil measurements (CPTs) are registered in large quantities. Because pile driving speed mainly depends on soil properties, this information can be used by a ML approach to estimate drive speed. Thus, the problem was that they were unable to predict pile drive time and needed data for their application to do so.
Second, they found a way to gather their data, as they needed data from pile driving, customer pile drive measurements, and CPTs to be able to predict pile drive time. For them, to be able to predict penetration speed, CPTs measurements had to be evaluated at a certain depth so that these evaluations could be used as input features for the ML model to predict a certain speed at this depth. This data was extracted from their database from previous projects.
Third, they chose how they were going to measure the success of their ML application. Voorbij’s problem was that they were unable to tell the time it would take to drive piles for projects quickly and precisely. Therefore, their goal was to be able to measure this time accurately and quickly using ML, thus the measurement of success was going to be the accuracy of these prediction measurements. This aligns with the company’s broader objective to deliver good service to their customers, spend their time efficiently, and accurately predict the course of a project.
Fourth and fifth, to be able to predict penetration speed, they chose for a Supervised Learning ML model that leverages the data from CPTs to predict the pile drive speed. The ANN adapts itself during training, such that for given CPT values, the correct pile drive speed is predicted. Voorbij used their training data for two distinctive relevant possible scenarios as to how their ML application can be applied in practice:
- Scenario 1: The client can use a few pile measurements at the start of an individual project as the training dataset. Based on this dataset, the ANN can predict the penetration speed for the piles that are driven in the remainder of the project. These penetration speed values can thereafter be used to improve the estimation of the total project time.
- Scenario 2: Another possible scenario would be to train the machine learning model on one or multiple projects to predict the penetration speed values at completely different locations. These predictions can then be used to estimate the total project time before the start of the project.
Sixth, a model was built with an ANN. To determine the optimal model, a little experimenting was done regarding the number of units per layer within the ANN. The value of each output layer of the model was the predicted penetration speed. To optimize predictions, a small part of the datasets was used as validation set, the performance of the model on this validation set was monitored during the training of the ANN. To prevent overfitting to the training set, training was stopped automatically after all data was ran through the model several times, while at the same time the validation set performance did not increase. To set a limited amount of training time, the maximum allowed number of training rounds (also called epochs) during training was set to a maximum.
And seventh, they drew their conclusions from the results of the model. The two different scenarios described in step 4 yielded different results when it came down to prediction accuracy:
- Individual projects: For these projects, the results of the test set are presented for the case where 10% of the total number of penetration speed measurements are used as training set to predict the remaining 90%. The output of the ANN penetration speed values is fitted to the training set measurements. After training, the ANN is able to predict the pile penetration speed at certain locations as a function of the depth at the test set locations. For one construction project, the ANN model was able to predict the pile penetration speed at the test set locations with a relative error of 10%.
- Multiple projects: In this scenario, a full set of penetration speed measurements from an entire area site is defined as the training set and the full set of measurements from another entire area site is defined as the test set. The output of the ANN penetration speed values is fitted to the training set measurements. In this scenario, the performance of the ANN decreases significantly (the relative error rises to 31%), compared to the individual project-scenario.
With these predicted penetration speed values, the total drive time can be predicted. The predicted total drive time can then be compared with the actual registered total drive time. The results from these total drive time estimations are displayed here for two separate projects with differing soil compositions.

Lack of accuracy on the right project can be explained by the fact that if the penetration speed at a certain moment is so low that it is close to zero, the machine cannot register this and rounds it to 0 m/s. This is also confirmed by these scatter plots displaying the registered drive time against the computing drive times. The blue dots denote that during these drives, the speed was always larger than 0 m/s and the red dots denote a speed of 0 m/s. On the right graph, the speed measurements from the lesser accurately predicted project are presented and explained. This exemplifies the importance of correct input data for the ML model.

The model is trained with relatively rudimentary training data within the VIKTOR app and is able to predict penetration speed values for a given CPT. The performance of the penetration speed prediction is maximized if a small sample of the pile field is used to train the model. This predicted penetration speed can then be used to predict the estimated total driving time.
Digit recognition
In the beginning we explained how ML could be used to classify for example numbers, faces, and more. Below is such an example of an application that can classify numbers. For this application, and SVC were used. Here, it can be seen in action.
What happens within the application is as follows: An image recognition task is performed on 64-pixel hand-written images of digits in the web application. The goal of the algorithm is to recognize for a given 64-pixel image, which digit is hand-written in the image. Here, an SVC model is trained on a dataset consisting of 1797 images with corresponding labels. The SVC is trained to recognize an image as a digit between 0 to 9. With this SVC model it is possible to achieve a classification accuracy of ~99% on new images, which the model has not ‘seen’ during training. In the application it is possible to train the model with hyperparameters that can be set in the app and this trained model can be directly deployed to recognize new images.
About VIKTOR
Developments regarding AI en ML are touching and will continue to touch all kinds of aspects in organizations. From what we have told you and what can be concluded from the example of Voorbij’s case, you can see that the possibilities of using ML techniques to automate all kinds of processes are extensive and beneficial. Therefore, the importance of finding a good way to gather, store, access and use data before you can unlock the powers of it and put it to work is undeniable.
That is where the VIKTOR platform comes in.
VIKTOR explained
VIKTOR is an application development platform that enables people to rapidly build their own online applications with a Python Software Development Kit (SDK). The VIKTOR platform is a place where people can centralize and distribute data, models, and analyses to others such that it acts as a single point of truth. Additionally, you can use the platform to integrate with data sources and all relevant software packages. In combination with the ability to automate and use algorithms, such as Machine Learning, you are able to find the best solution fast. With a VIKTOR application, you can interpret data quick and easy by means of understandable insights provided on an interactive and customizable dashboard, which enables you to turn your knowledge into an asset!
Want to know more?
VIKTOR is on a mission to unleash the world’s real engineering potential. That is why we are developing a platform where engineers can build their own web-based applications using Python. We work closely together with for example engineering, construction, and manufacturing companies and help them boost their digital transformation. We would love to hear your feedback on our ideas and invite you to try out the platform and help us create the perfect tools that enable you to automate the boring, engineer the awesome!